Ever thought about listening to your documents instead of reading them! Especially during long commutes or when the eyes feel tired from reading on screens all day. Whether it's a PDF report, a Word document, a PowerPoint presentation, or a plain text file, converting these into audio can be really useful for productivity and accessibility.
Lets create a serverless solution using AWS Polly that automatically turns uploaded documents into MP3 audio files. AWS Lambda handles the processing, and Amazon S3 provides the storage—without the need to manage any servers! This setup changes the way content is consumed during free time.
What is AWS Polly?
AWS Polly is Amazon's cloud-based text-to-speech service that converts written text into speech that sounds very natural.Text-to-speech technology has improved a lot, and AWS Polly is a great example of that. Using advanced deep learning, Polly produces voices in multiple languages and accents that are pleasant to listen to—unlike the robotic voices of the past.
The service helps developers build applications that can speak, create speech-enabled products, and make content more accessible. Whether you're making a news reader app, an educational tool, or an accessibility feature, Polly provides the tools needed to convert text into lifelike speech.
- Natural-sounding voices: Choose from a variety of lifelike voices in multiple languages
- Real-time streaming: Convert text to speech as it is created
- SSML support: Control how text is spoken using Speech Synthesis Markup Language
- Multiple output formats: Generate audio in MP3, OGG, or PCM formats
- Neural voices: High-quality voices that sound even more natural
Prerequisites
- An AWS account (the free tier is ideal for this project)
- Basic knowledge of AWS services like S3 and Lambda
- Python 3.8 or higher installed on your computer
Required Python Libraries
- PyPDF2: For extracting text from PDF files
- python-docx: For extracting text from Word documents
- python-pptx: For extracting text from PowerPoint presentations
Creating the S3 Bucket Structure
Start by setting up the S3 bucket with the required folder structure. This bucket will act as both the input and output location for documents and audio files.
First, create an S3 bucket called text-audio-converters. Inside this bucket, create two folders: input and audio. The input folder will hold the documents to be converted (PDFs, Word docs, PowerPoint presentations, and text files), while the audio folder will store the converted MP3 files. This simple structure keeps the workflow organized and makes it easy to track both original documents and their audio versions.
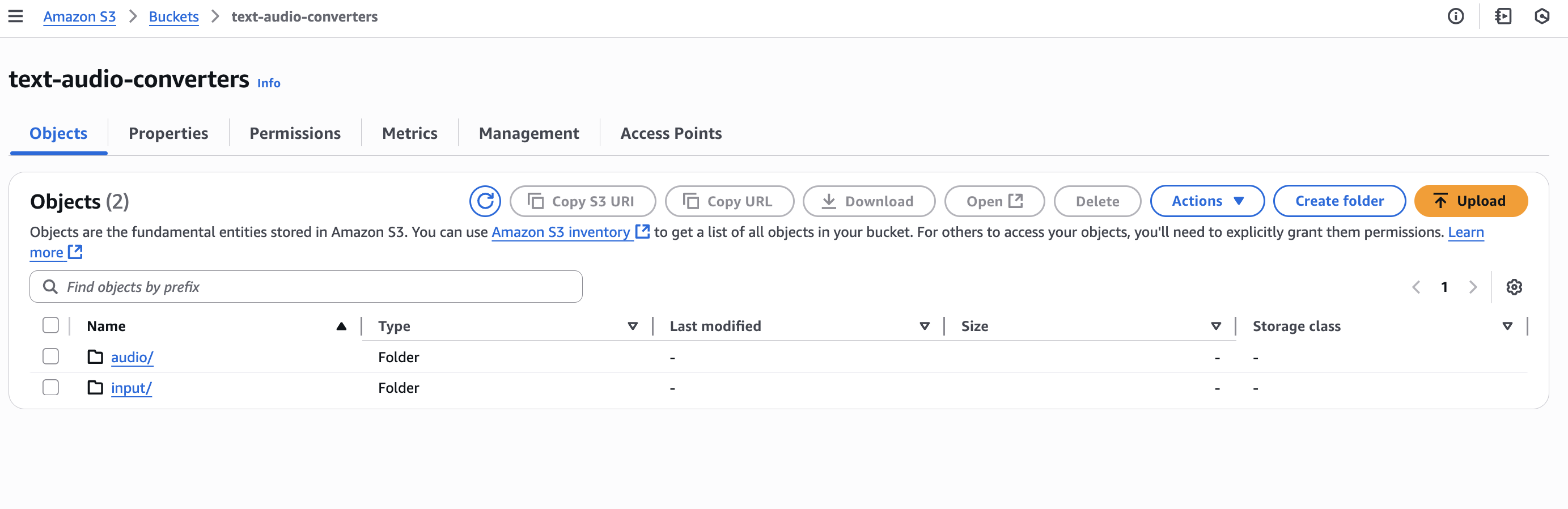
Creating Layers
Next, create the Lambda layers needed for document processing. Lambda layers allow additional libraries and dependencies to be included in Lambda functions without including them in the deployment package.
- DOCX Layer: Create a zip file containing the python-docx library In AWS Lambda, go to Layers and create a new layer named docx-layer Upload the zip file and select the Python 3.12 runtime
- PPTX Layer: Create a zip file containing the python-pptx library Create a new layer named pptx-layer Upload the zip file and select the Python 3.12 runtime
- PDF Layer: Create a zip file containing the PyPDF2 library Create a new layer named pdf-layer Upload the zip file and select the Python 3.12 runtime
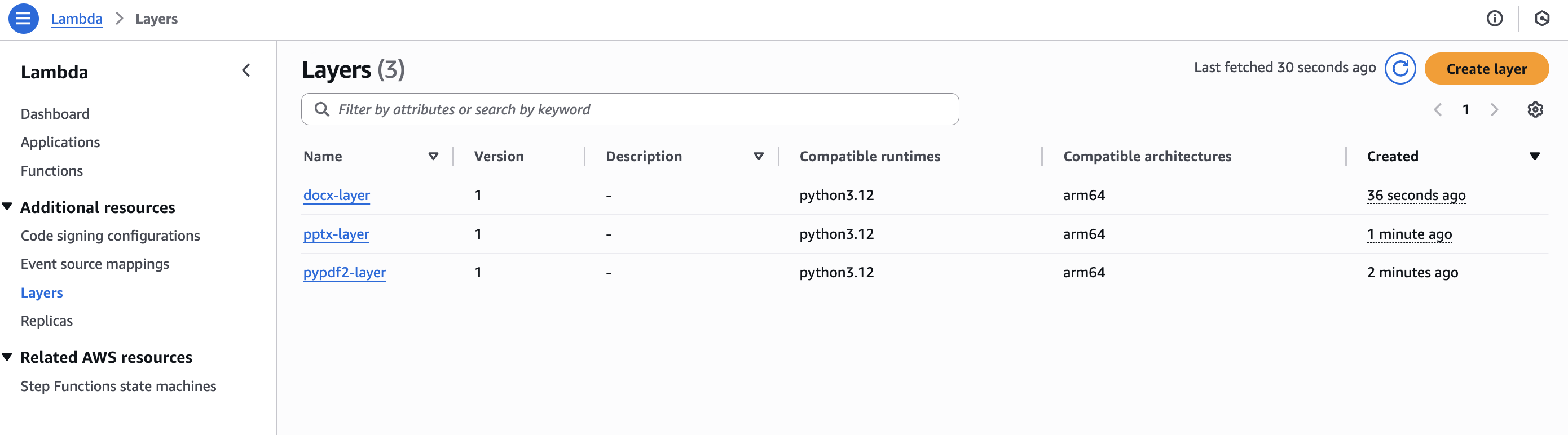
These layers let the Lambda function extract text from different document formats without having to include all the libraries in the main function code.
Creating the Lambda Function
The core processing engine is the Lambda function. This function handles the entire conversion process, from text extraction to audio generation.
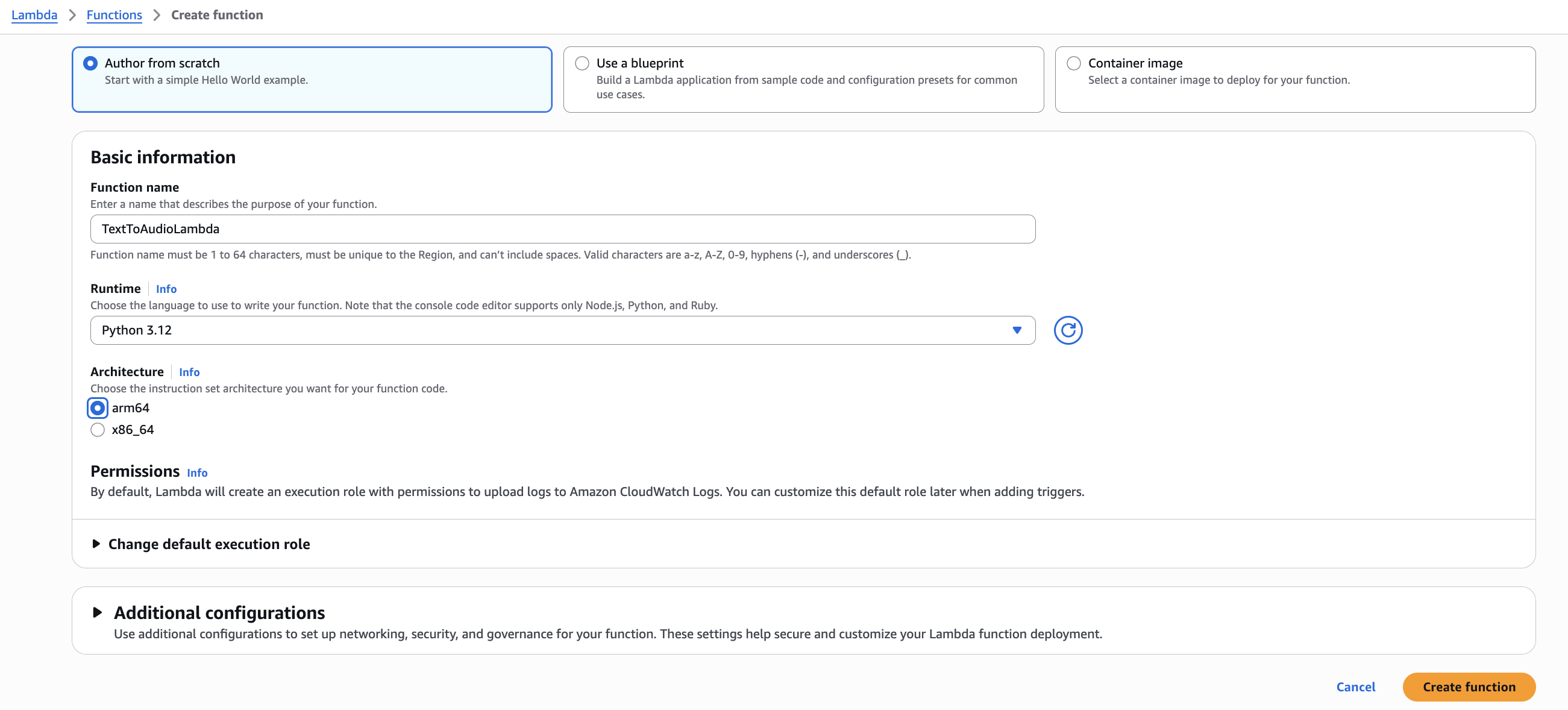
In the AWS Lambda console, click "Create function" and choose "Author from scratch". Name the function TextToAudioLambda, select Python 3.12 as the runtime, and choose the ARM64 architecture for better performance and cost efficiency. For permissions, select "Create a new role with basic Lambda permissions" and click "Create function". This function will be the core of the document-to-audio conversion system, processing each file uploaded to the S3 bucket.
Setting Up the Lambda Trigger
Configure the Lambda function to trigger automatically when a file is uploaded to the S3 bucket.
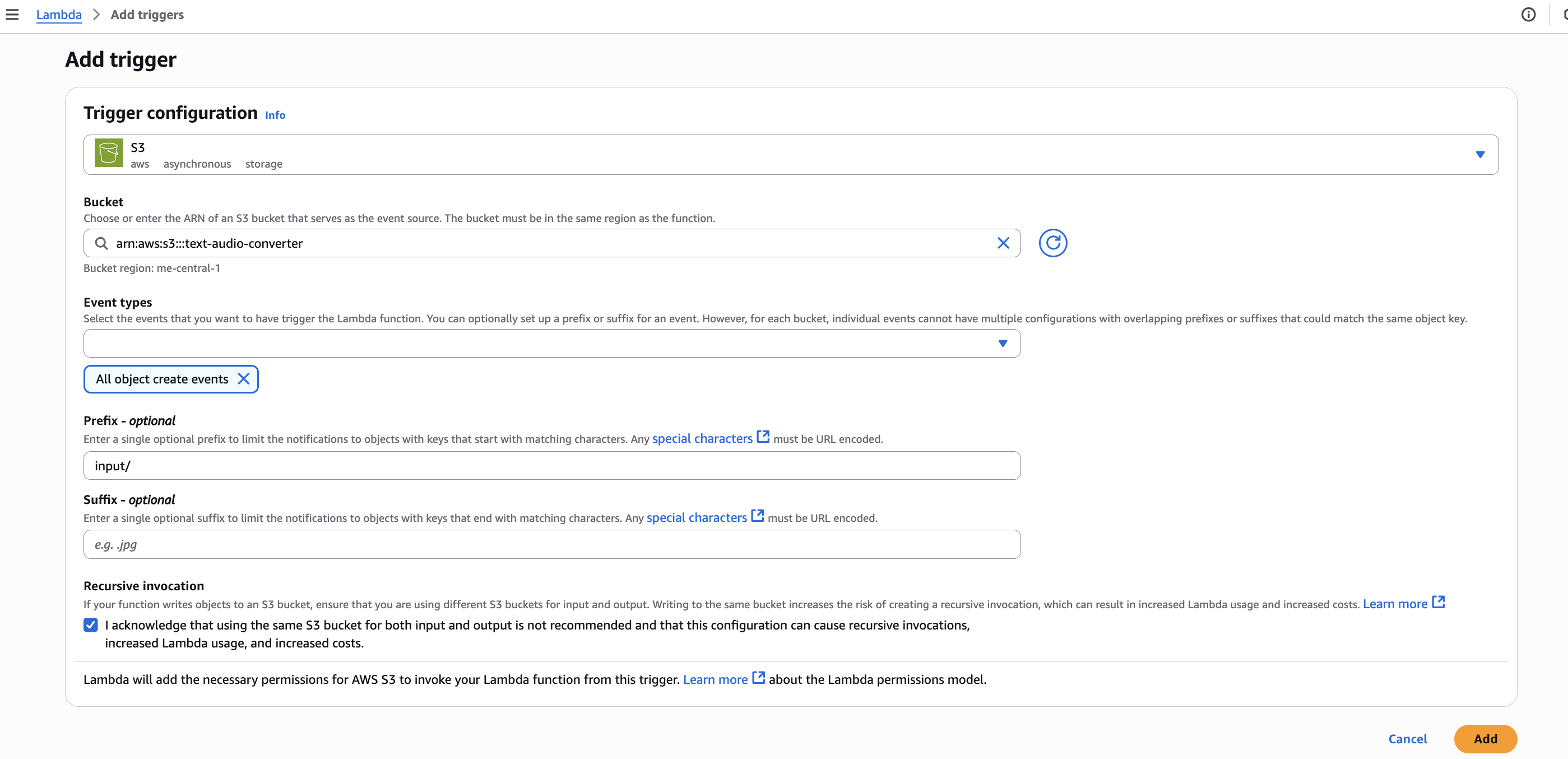
- In the Lambda function designer view, click "Add trigger"
- Select S3 as the trigger source
- Choose the text-audio-converters bucket as the event source
- For event type, select "All object create events"
- Set the prefix to input/ to make sure only files in the input folder trigger the function
- Acknowledge the recursive trigger warning and click "Add"
Attaching Layers to Lambda Function
With the function created, attach the layers prepared earlier.
In the Lambda function view, scroll down to the "Layers" section and click "Add a layer". Under "Custom layers", select the docx-layer and click "Add". Repeat this process for the pptx-layer and pdf-layer. These layers provide the necessary libraries for the function to extract text from different document formats. By separating them into layers, the main function code remains clean and focused on the conversion logic.
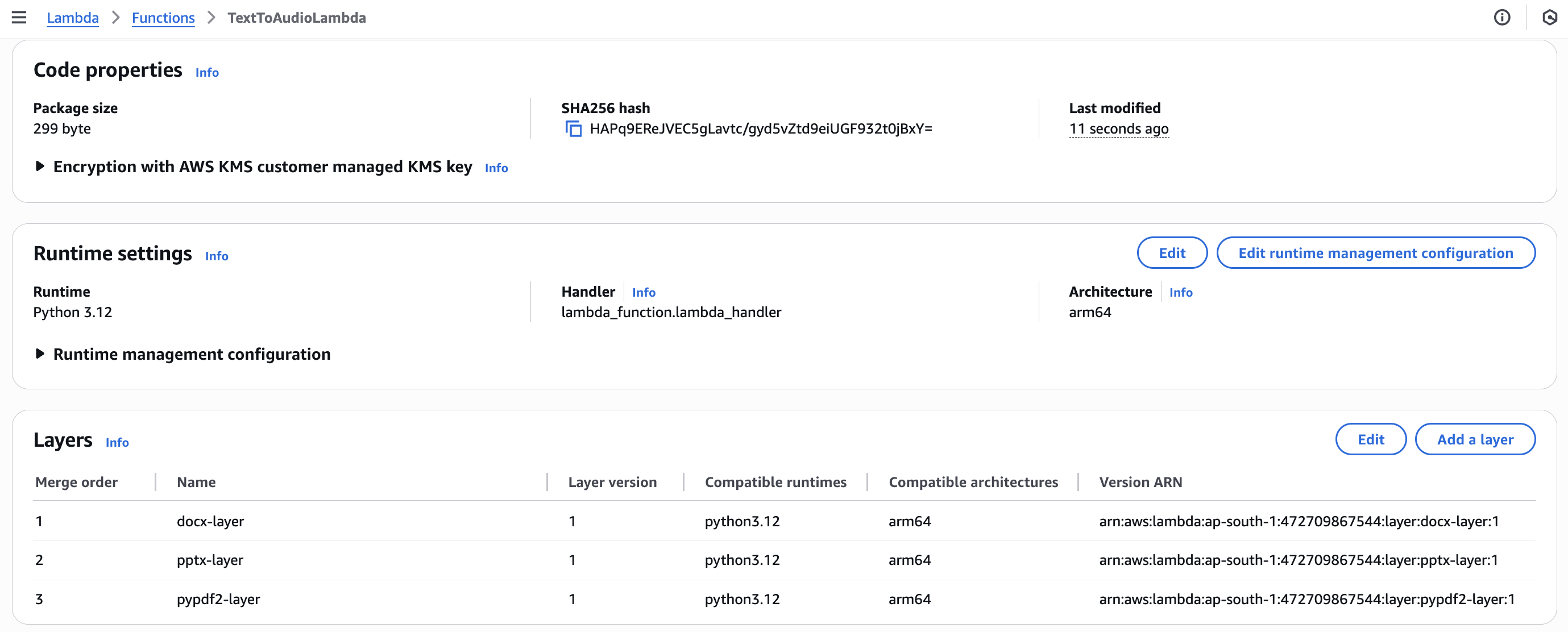
Attaching Permissions to Lambda Role
The Lambda function needs permissions to access S3 and Polly services.
In the Lambda function view, go to the "Configuration" tab and click "Permissions". Click on the role name to open the IAM role in a new tab. In the IAM role view, click "Add permissions" and select "Attach policies".
Search for and attach the following policies: AmazonS3FullAccess, AWSLambdaFullAccess, and AmazonPollyFullAccess. These policies give the function the necessary permissions to read from and write to S3 buckets, run Lambda functions, and use the Polly text-to-speech service.
Lambda Code
The code that powers the conversion function handles everything from downloading the file from S3 to extracting text and converting it to speech.
import json
import boto3
import os
import logging
from pptx import Presentation
from docx import Document
from PyPDF2 import PdfReader
from io import BytesIO
import urllib.parse
# Set up logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# AWS clients
s3 = boto3.client('s3')
polly = boto3.client('polly', region_name='me-south-1')
# Environment Variables
INPUT_FOLDER = os.environ.get('INPUT', 'input/')
AUDIO_FOLDER = os.environ.get('AUDIO', 'audio/')
DEFAULT_VOICE = os.environ.get('DEFAULT_VOICE', 'Joanna')
def extract_text_from_docx(docx_path):
doc = Document(docx_path)
full_text = []
for para in doc.paragraphs:
if not para.text.strip():
continue
full_text.append(para.text.strip())
return "
".join(full_text)
def extract_text_from_pptx(filepath):
prs = Presentation(filepath)
text = []
for slide in prs.slides:
for shape in slide.shapes:
if not hasattr(shape, "text") or not shape.text.strip():
continue
shape_text = shape.text.strip()
# Treat as bullet or content
lines = [line.strip() for line in shape_text.splitlines() if line.strip()]
for line in lines:
text.append(line)
return "
".join(text)
def extract_text_from_pdf(filepath):
reader = PdfReader(filepath)
text = []
for page in reader.pages:
page_text = page.extract_text()
if page_text:
text.append(page_text.strip())
return "
".join(text)
def lambda_handler(event, context):
try:
logger.info("Event received: %s", json.dumps(event))
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'])
logger.info("Processing file from bucket: %s, key: %s", bucket, key)
if not key.startswith(INPUT_FOLDER):
return {'statusCode': 400, 'body': f'File must be in the {INPUT_FOLDER} folder.'}
local_path = f"/tmp/{os.path.basename(key)}"
s3.download_file(bucket, key, local_path)
logger.info("File downloaded to: %s", local_path)
file_ext = key.lower().rsplit('.', 1)[-1]
logger.info("Detected file extension: %s", file_ext)
input_text = ""
if file_ext == 'txt':
with open(local_path, 'r', encoding='utf-8') as f:
input_text = f.read()
elif file_ext == 'docx':
input_text = extract_text_from_docx(local_path)
elif file_ext == 'pptx':
input_text = extract_text_from_pptx(local_path)
elif file_ext == 'pdf':
input_text = extract_text_from_pdf(local_path)
else:
return {'statusCode': 400, 'body': 'Unsupported file format. Only .txt, .pdf, .docx, and .pptx are allowed.'}
if not input_text.strip():
return {'statusCode': 400, 'body': 'The document is empty or unreadable.'}
logger.info("Synthesizing speech with voice %s", DEFAULT_VOICE)
response = polly.synthesize_speech(
Text=input_text,
OutputFormat='mp3',
VoiceId=DEFAULT_VOICE,
TextType='text'
)
if "AudioStream" not in response:
logger.error("Polly did not return AudioStream")
return {'statusCode': 500, 'body': 'Failed to generate audio'}
audio_stream = response['AudioStream']
filename_wo_ext = os.path.basename(key).rsplit('.', 1)[0]
audio_key = f'{AUDIO_FOLDER}{filename_wo_ext}.mp3'
s3.put_object(
Bucket=bucket,
Key=audio_key,
Body=audio_stream
)
logger.info("Audio file saved to S3 at key: %s", audio_key)
return {
'statusCode': 200,
'body': f'Audio saved at {audio_key}'
}
except Exception as e:
logger.exception("Unhandled exception occurred:")
return {
'statusCode': 500,
'body': f'Error: {str(e)}'
}How the Code Works
The code begins by configuring logging and setting up AWS clients for S3 and Polly. It then defines functions to extract text from various document types:
- extract_text_from_docx reads a Word document and retrieves text from each paragraph
- extract_text_from_pptx processes a PowerPoint presentation, extracting text from each shape on every slide
- extract_text_from_pdf handles PDF files by reading text from each page
The main lambda_handler function is activated when a file is uploaded to S3. It downloads the file to a temporary location, identifies the file type, and uses the corresponding function to extract the text. The extracted text is then sent to AWS Polly to generate speech, and the resulting MP3 file is saved back to S3 in the audio folder. The code incorporates error handling and logging to assist in identifying and resolving any issues that may arise during the process.
Testing the Solution
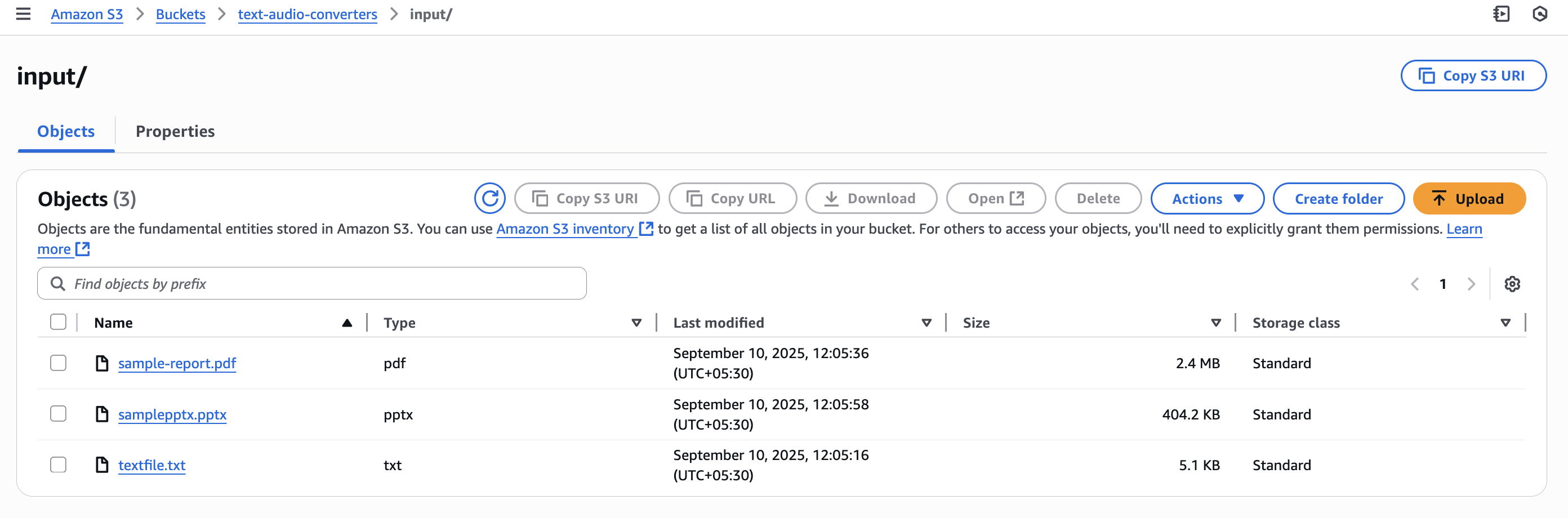
The solution can be tested by uploading sample documents to the input folder of the S3 bucket. Different file types can be tried such as a PDF report, a Word document, a PowerPoint presentation, or a plain text file. As soon as a file is uploaded, the Lambda function will be triggered automatically. The execution process can be monitored using the Lambda console's CloudWatch logs to track the conversion progress.
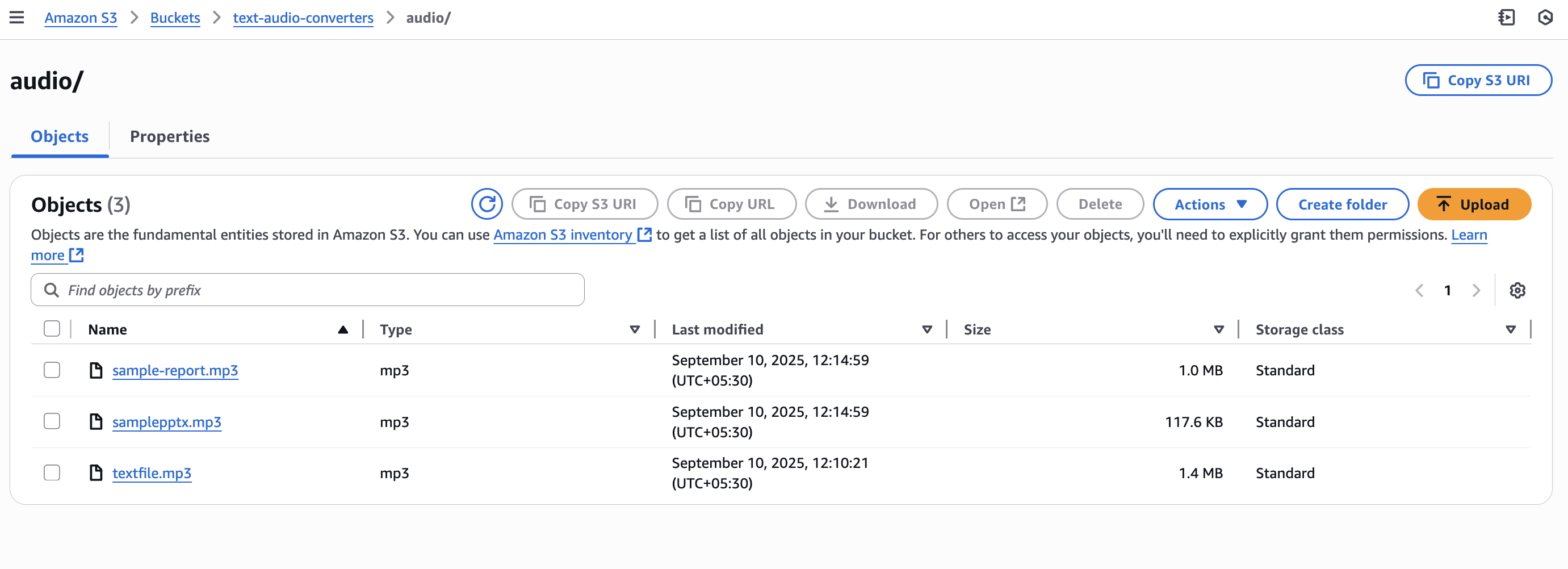
After the Lambda function completes its task, the audio folder in the S3 bucket will contain the converted files. MP3 files corresponding to each uploaded document will be found. The filenames will match the original document names but with .mp3 extensions. For instance, if "quarterly-report.pdf" was uploaded, "quarterly-report.mp3" will be found in the audio folder. These MP3 files can be downloaded, played, or shared like any other audio file. The documents can be listened to on a phone, computer, or any device that supports audio playback.
Conclusion
This completes the setup of a serverless document-to-audio conversion system using AWS Polly. This solution automatically processes uploaded documents such as PDFs, Word documents, PowerPoint slides, and text files, converting them into high-quality MP3 audio files.
- Fully Automated: The system operates without any manual intervention once set up.
- Scalable: AWS Lambda automatically adjusts to handle multiple file uploads at the same time.
- Cost-effective: With AWS's pay-as-you-go pricing and free tier, this solution is affordable for most use cases.
- Accessible: By converting text to audio, content becomes available in a format that can be consumed while multitasking or by visually impaired users.
